Results
 All models were trained solely on interactions with
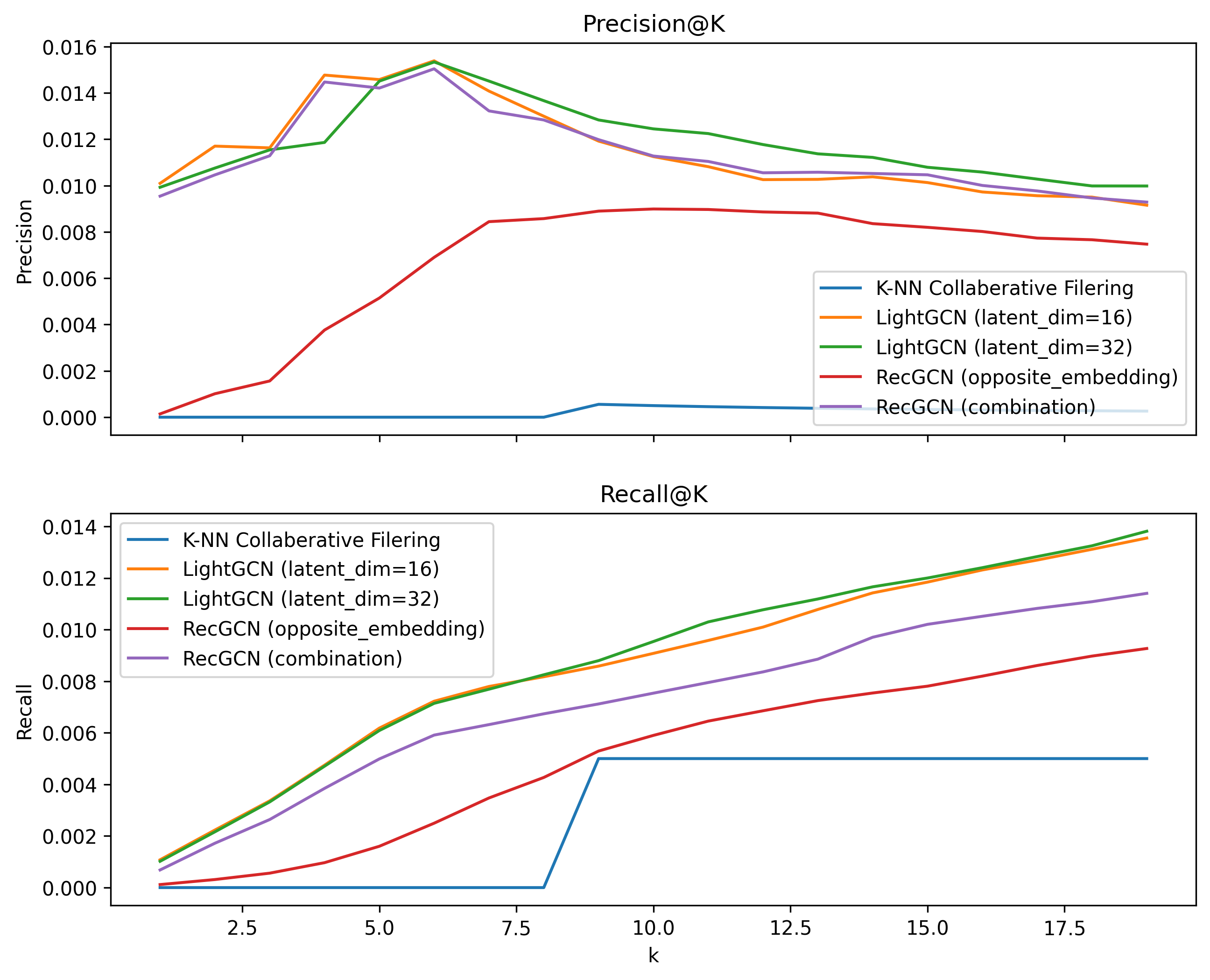
All models were trained solely on interactions with is_train = True. For models that support iterative training, we saved the best model based on its Precision@10 performance on interactions with is_validation = True. Models were finally evaluated on interactions with is_test = True. The results are shown above for recommendations at several values.
The first thing to note is that K-NN collaborative filtering did not work well with this dataset, performing far worse then every GNN model. Further research reveals that this may be due to the fact that the dataset is extremely sparse, with only of test users and of test recipes even showing up in the training set. With both needed to even produce a recommendation, this results in a very small number of possible interactions.
This finding also explains LightGCN's great performance, which is comparable to the original LightGCN paper's results on the Amazon-Book dataset (another sparse dataset).
Surprisingly, LightGCN performed well enough to outperform every version of RecGCN. We believe this may be similar to the reason LightGCN outperformed many of its predecessors: the simplicity of the architecture. One common issue we ran into during training is that our models quickly began to overfit the data, resulting in poor performance on the validation set. Simpler models are able to sidestep this issue through their inability to model complex relationships.
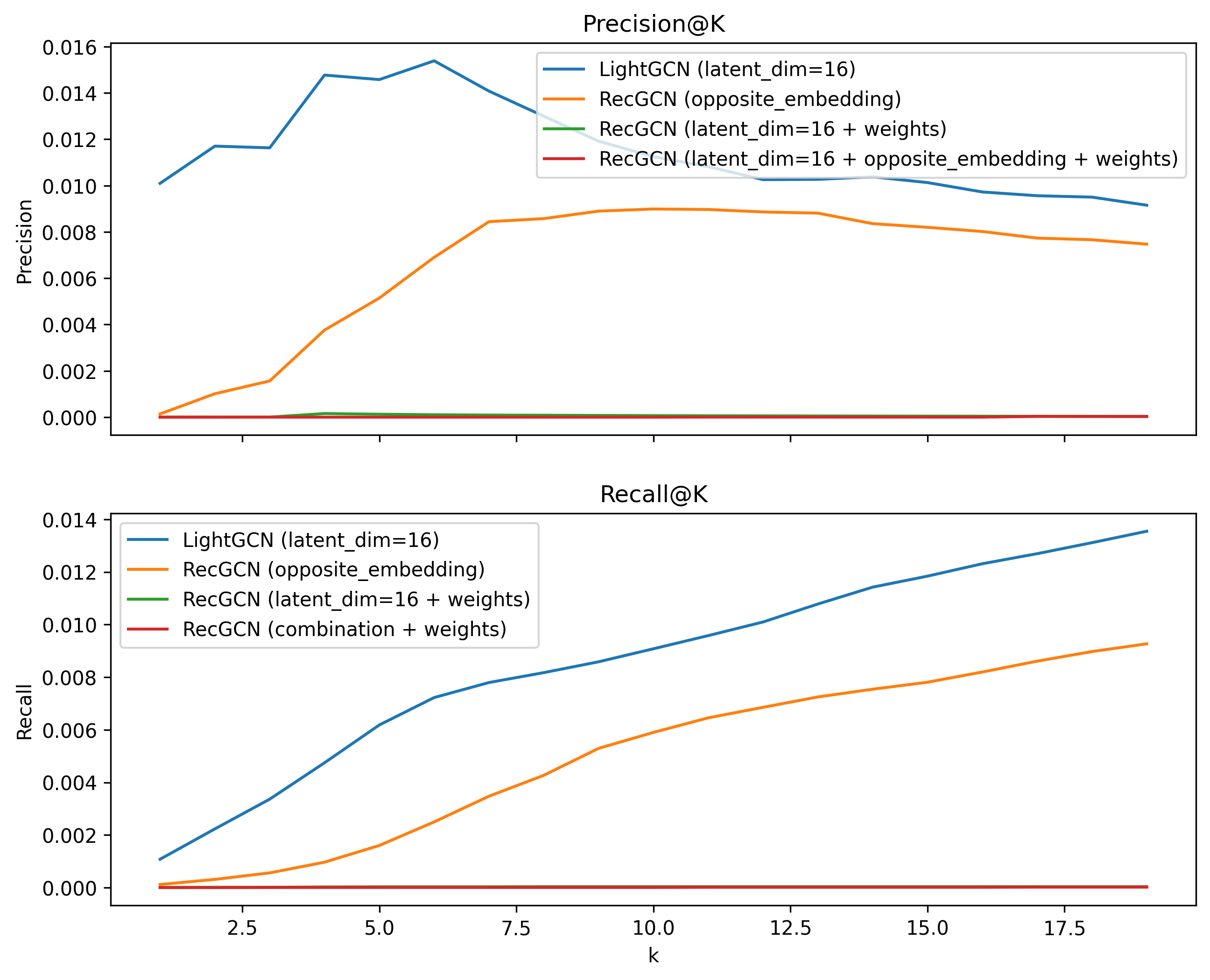
In order to further investigate how each RecGCN alteration affected the model, we also performed an analysis on each of the changes we made. The results are shown above.
The first thing to note is that the addition of review weights destroyed the model's performance. We believe this may be due to multiple high reviews exponentially scaling certain embeddings, resulting in a complex relationship that the model is unable to model. We talk more about possible solutions to this issue in the future work section.
The second thing to note is that the addition of recipe features did not have a significant impact on the model's performance. If anything, it slightly decreased the model's performance. We believe this may be due to the fact that the features we have available to us aren't as descriptive as the latent variables learned by the model. For example, LightGCN may learn that a user prefer's "healthier" recipes, but a opposite embedding RecGCN model can only learn whether a user likes recipes low in fat.